
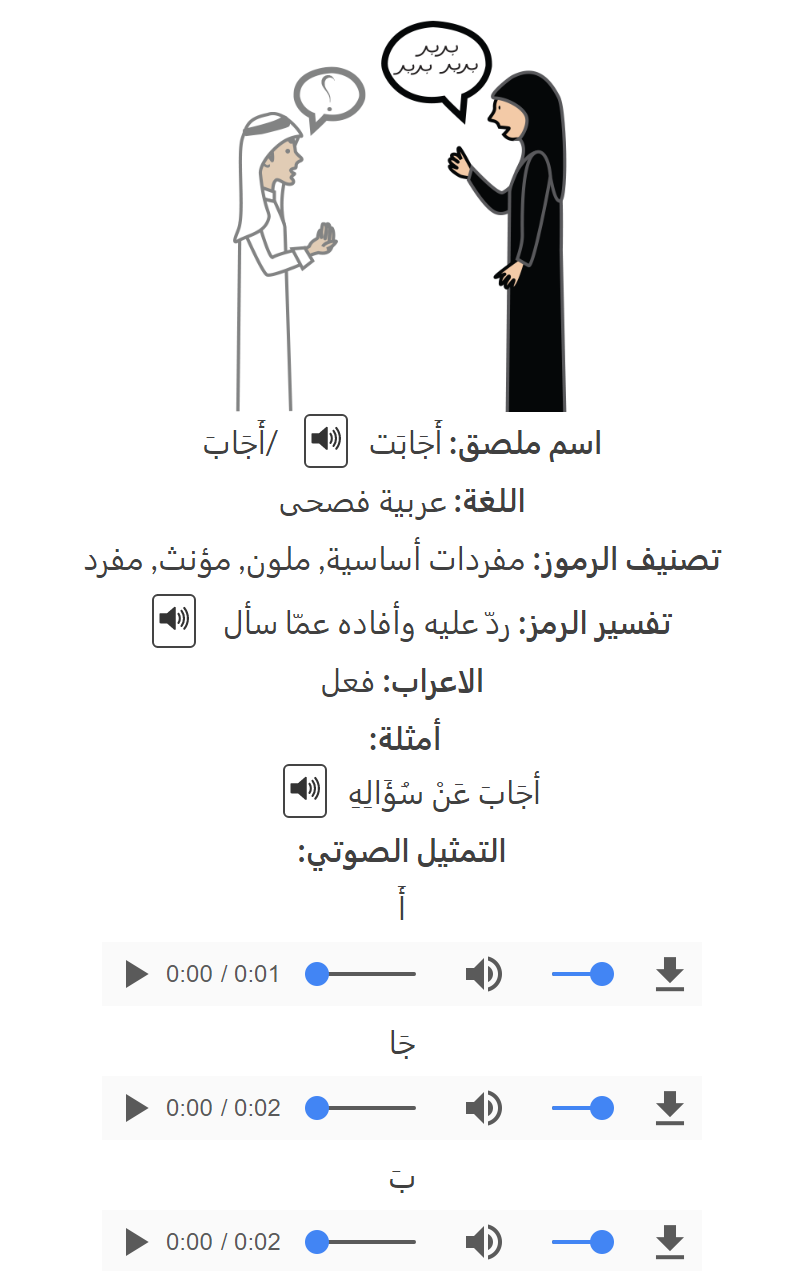
 If you have been using our Arabic symbols page you will have noticed that we have made every phoneme for our lexical entries available as a sound file, so that you can hear how it is pronounced. You can see the audio links at the bottom of the symbol for ‘respond’ in the picture beside this text. This can help those who have literacy skills difficulties as well as those wish to learn Arabic.
If you have been using our Arabic symbols page you will have noticed that we have made every phoneme for our lexical entries available as a sound file, so that you can hear how it is pronounced. You can see the audio links at the bottom of the symbol for ‘respond’ in the picture beside this text. This can help those who have literacy skills difficulties as well as those wish to learn Arabic.
Nawar, who has been part of our Tawasol Symbols project from the beginning at the same time as successfully completing his PhD, has made this possible with the development of an Arabic Speech Corpus with support from the University of Southampton and MicrolinkPC.
The synthesised speech output that results from this corpse is a very natural sounding voice, recorded using Levantine Arabic, as heard in and around Damascus. Levantine Arabic is considered one of the three main Arabic dialects and differs from Gulf Arabic in some aspects of grammar and pronunciation although when phonemes are read aloud, they are often nearer Modern Standard Arabic and when combined there is less dialectal impact.
The corpus has been made available for download as a zip file and is released under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License. As the Arabic Speech Corpus website says the packages includes:
- 1813 .wav files containing spoken utterances.
- 1813 .lab files containing text utterances.
- 1813 .TextGrid files containing the phoneme labels with time stamps of the boundaries where these occur in the .wav files. These files can be opened using Praat software.
- phonetic-transcript.txt which has the form “[wav_filename]” “[Phoneme Sequence]” in every line.
- orthographic-transcript.txt which has the form “[wav_filename]” “[Orthographic Transcript]” in every line. Orthography is in Buckwalter Format which is friendlier where there is software that does not read Arabic script. It can be easily converted back to Arabic.
- There is an extra 18 minutes of fully annotated corpus (separate from above, but with the same structure as above) which was used to evaluate the corpus (see PhD thesis). Feel free to use this in your applications.
Please contact Nawar Halabi by email for further information.