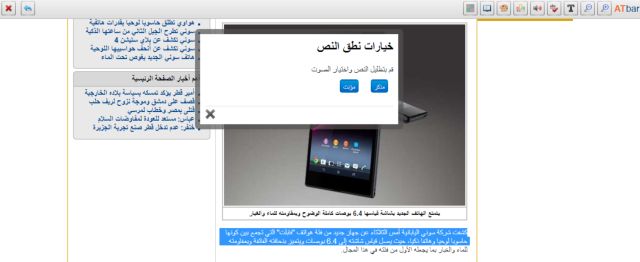
A group of us met up over lunch to test ATbar on a series of portable devices. This was very much a ‘beta’ testing session with critical friends. We filled in a test form and the results were analysed.
Some problems still need to be resolved namely:
size of icons on smart phones
selecting text for text to speech – Samsung Galaxy with Honeycomb does not work
exiting ATbar does not necessarily mean the speech stops
Windows tablet using Chrome does not allow for zoom by stretch and pinch
iPad with Safari seems to produce variable results, in particular with text highlighting
highlighting text for text to speech is not easy
It is clear that the only way ATbar can work with mobile web browsers is to have the toolbar embedded in the website’s code. It cannot be added to mobile browsers as a bookmarklet. If the toolbar is embedded the toolbar will load as it does on a desktop browser offering coloured overlays, text to speech and other text enhancements and accessibility options.
ATbar has taken on a new look that will work on mobile technologies – it has become responsive – we are testing it at present but in the coming weeks we hope to release a version that allows tablet and mobile phone users to easily access all parts of ATbar including text to speech with a new player.
It may not be necessary to have text to speech as an option on some tablets and mobile as operating systems such as iOS offer VoiceOver and a speak feature when sections of web pages are highlighted but some other mobile operating systems do not offer this option. You can now highlight words and select the speaker icon and ATbar will read out the content.
We are still trying to resolve the issue of adding bookmarks to mobile web browsers but this is a challenge that we reckon we should be able to overcome! Watch this spot.
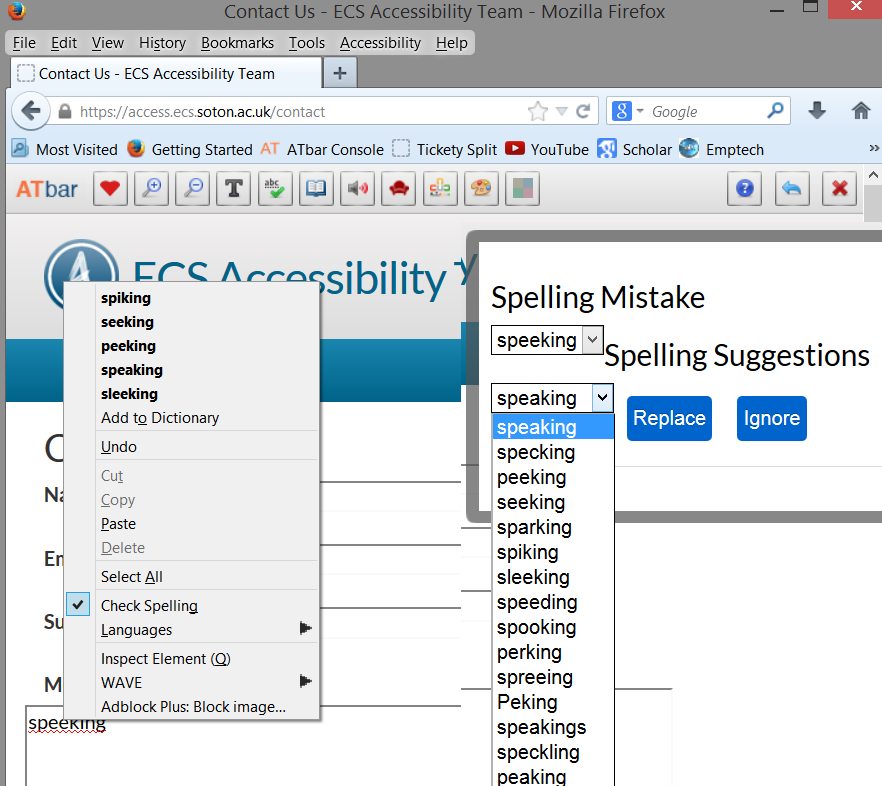
Other updates have included improved design for the spell checker with easier to read drop down boxes and other dialog boxes are becoming easier to use being less affected by websites cascading style sheets. It has also been noted that the ATbar spell checker often catches misspellings more accurately than some browser options! The spelling checker has a way of learning from mistakes thanks to the collection of the mistakes collected – when used it asked users to accept the correction each time – now it will only asks once.
Obviously all these aspects of ATbar will be available in Arabic and English. It is hoped that when we have our symbol dictionary working in web pages, ATbar will help users select symbols with speech output.
We are really exploring other voices for ATbar and felt that we needed some comparisons. The Speech Accent Archive has an interesting paragraph in English that uses nearly all the available phonemes in the language and provides users with a range of accents saying these words:
Please call Stella. Ask her to bring these things with her from the store: Six spoons of fresh snow peas, five thick slabs of blue cheese, and maybe a snack for her brother Bob. We also need a small plastic snake and a big toy frog for the kids. She can scoop these things into three red bags, and we will go meet her Wednesday at the train station.
Starting with English is the easy option as we have this paragraph to test various speech synthesisers, although many of the test sites limit the number of characters allowed for testing the voices so the text has been truncated.
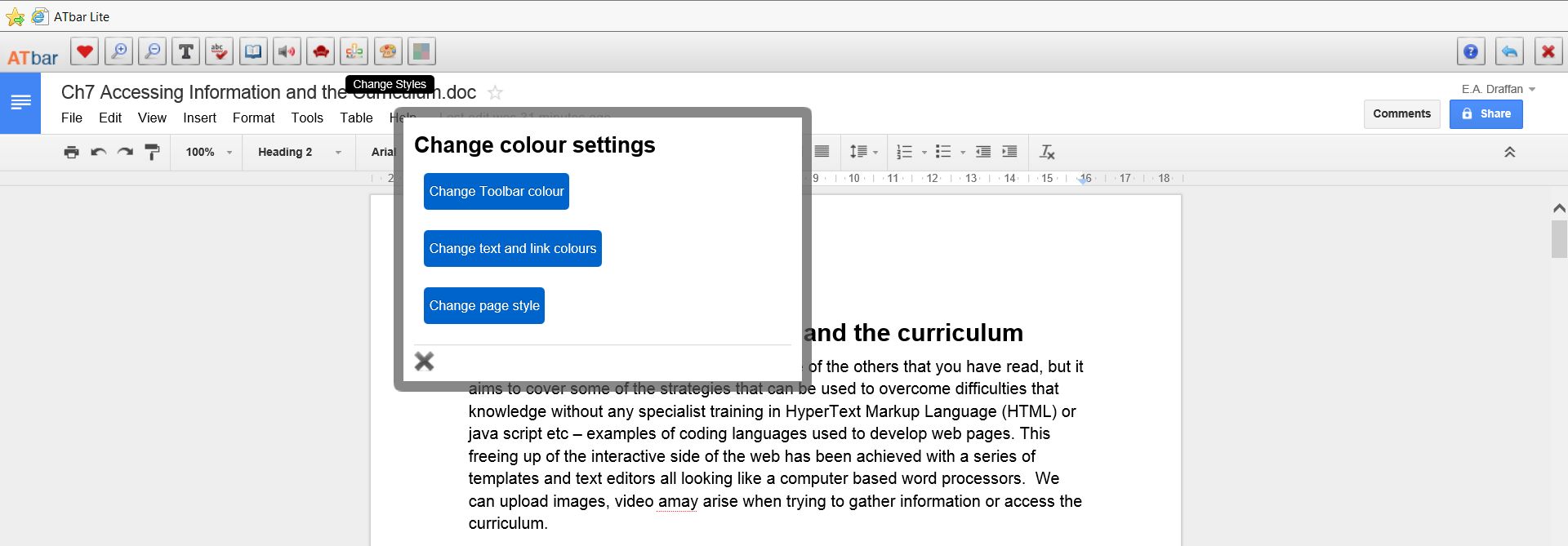
There have been recent updates to make the tool-bar more robust and compatible with browsers and the results have meant increased access to Google docs, Facebook (except Chrome at present) and Twitter – the text to speech and word prediction work when you change the background look and feel using the painter’s palate (change page style). The colour overlay can be toggled on an off for all websites and works with click through so you can go to another site even if you have the coloured overlay in place.
Work on the style sheet issues has also meant that the dialog boxes in ATbar do not always take on the style sheet of the target website. This also saves time when implementing new plugins and adding new things to the tool-bar as there are less style clashes so it is easier to customise the tool-bar for particular websites.
The latest version of the Festival Speech Synthesis System is now available as an option on the ATbar Market place website. The Festival plugin works in a similar way to the commercial Acapela TTS plugin.
ATbar now works with all the free speech synthesisers such as eSpeak and Mbrola but the quality of some of the voices is still a challenge for most listeners.
This month’s maintenance for the ATbar has included the updating of the wiki to include the instructions as a link from the toolbar with a small question mark icon. This has been completed in both Arabic and English and came about thanks to a question that we received via the contact form. The latter now also has our address as requested.
We also had a question about making toolbars in the market place and we have been updating the site to ensure that new toolbars can be saved as there seemed to be a problem with this aspect of the site. Making ones own toolbar is easy with a simple install to the bookmark or favorites area within the browser.
Both Nawar and Magnus have been looking into issues that affect the toolbar in terms of its presentation, such as cascading style sheets causing buttons and text to change. We are trying to find a way of eliminating these difficulties but it is easier said than done!
Nawar has also be researching issues around free and open source TTS voices to see if there are any new options or ways of developing ones ourselves. Not easy!
We have had a request for the story of ATbar and are looking forward to hearing when this will be published! Whilst researching for this article we also checked the statistics and found that we have had around 2,800 visitors to the download page (where the embed code is situated) in the last year, 1,125 WordPress plugin downloads. The total statistics for the English and the Arabic ATbar show that it has been used on 160,000 different sites and has had over 6.7 million uses in the last three years.
Nawar Halabi has very kindly provided an introductory video of the Arabic version of ATbar and we have uploaded it to YouTube.
YouTube video overview of ATbar in Arabic
Nawar has also been testing the Arabic version as part of our maintenance programme. We have found some issues with Arabic mis-aligned text at times and there are occasions when the CSS of the website needs to be isolated from the toolbar. Otherwise all the plugins appear to have worked well in the last few months.
Testing the Arabic dictionary
Testing the spell checker, text to speech and word prediction.
Where failures were reported these were double checked and found to be due to the word not being a partial word or not being in the dictionaries – usually due to an English speaking person trying to cut and past Arabic words!
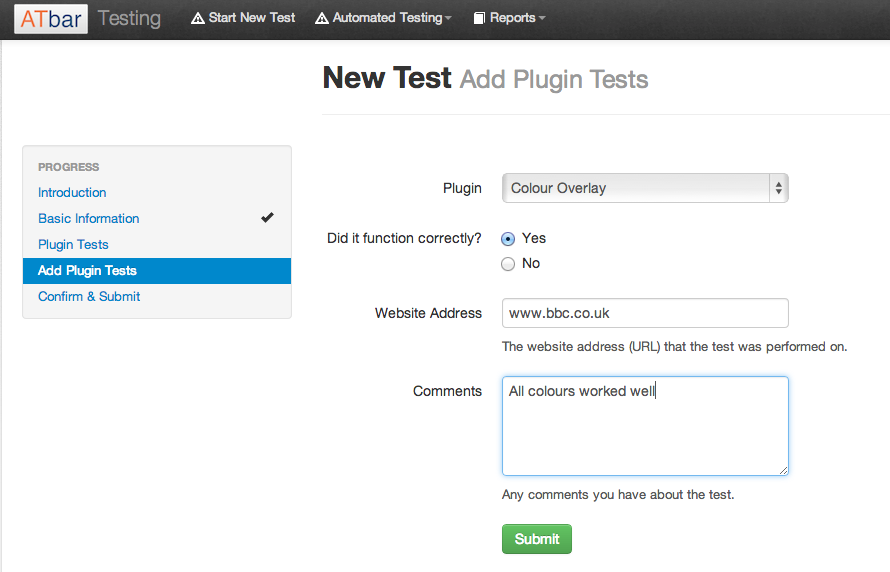
Up to this point we have had to test all the ATbar plugins manually for both languages. This takes time and there is no way of recording the results in order to share the information other than in Excel spreadsheets or Word documents.
Online Testing
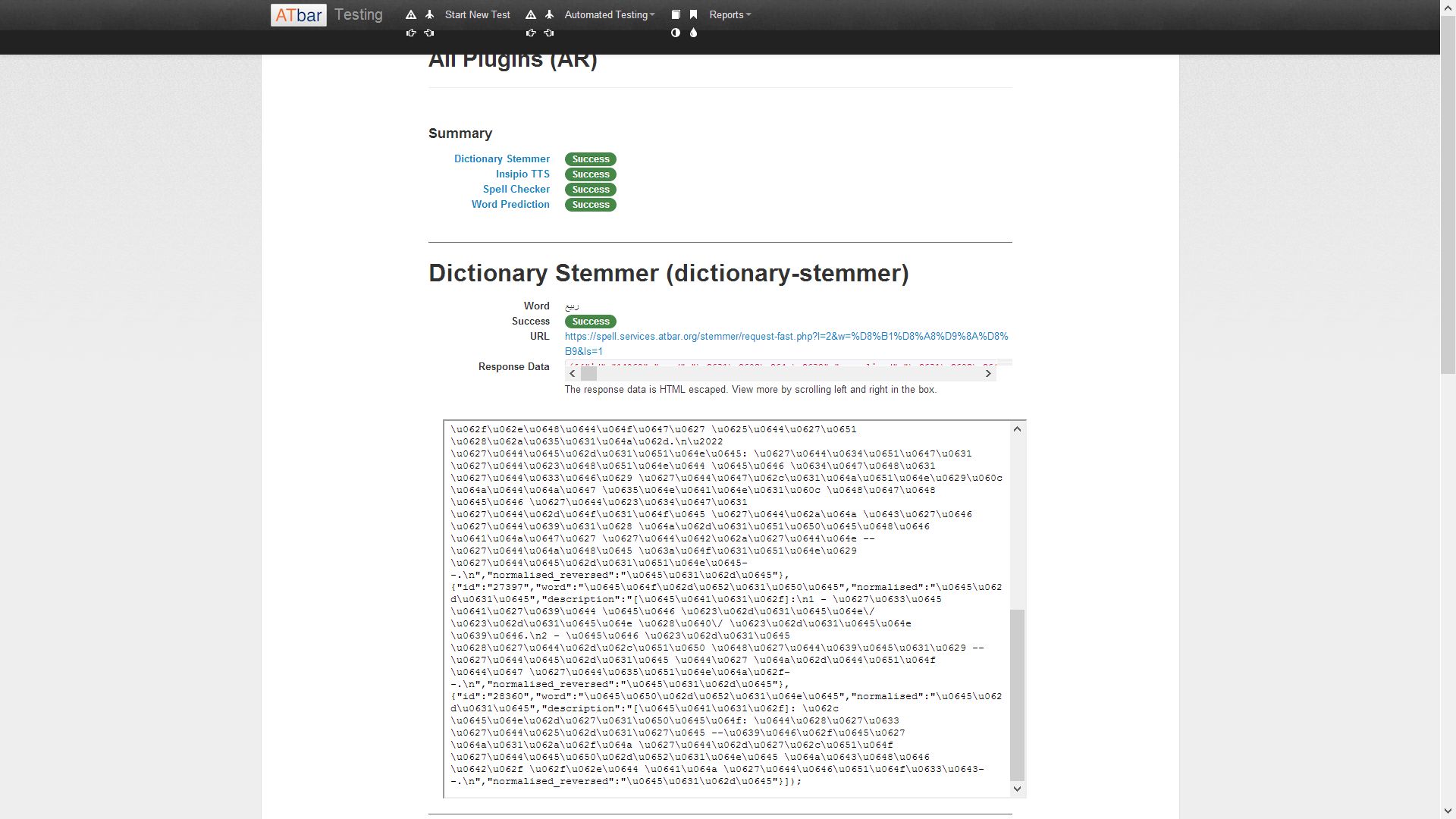
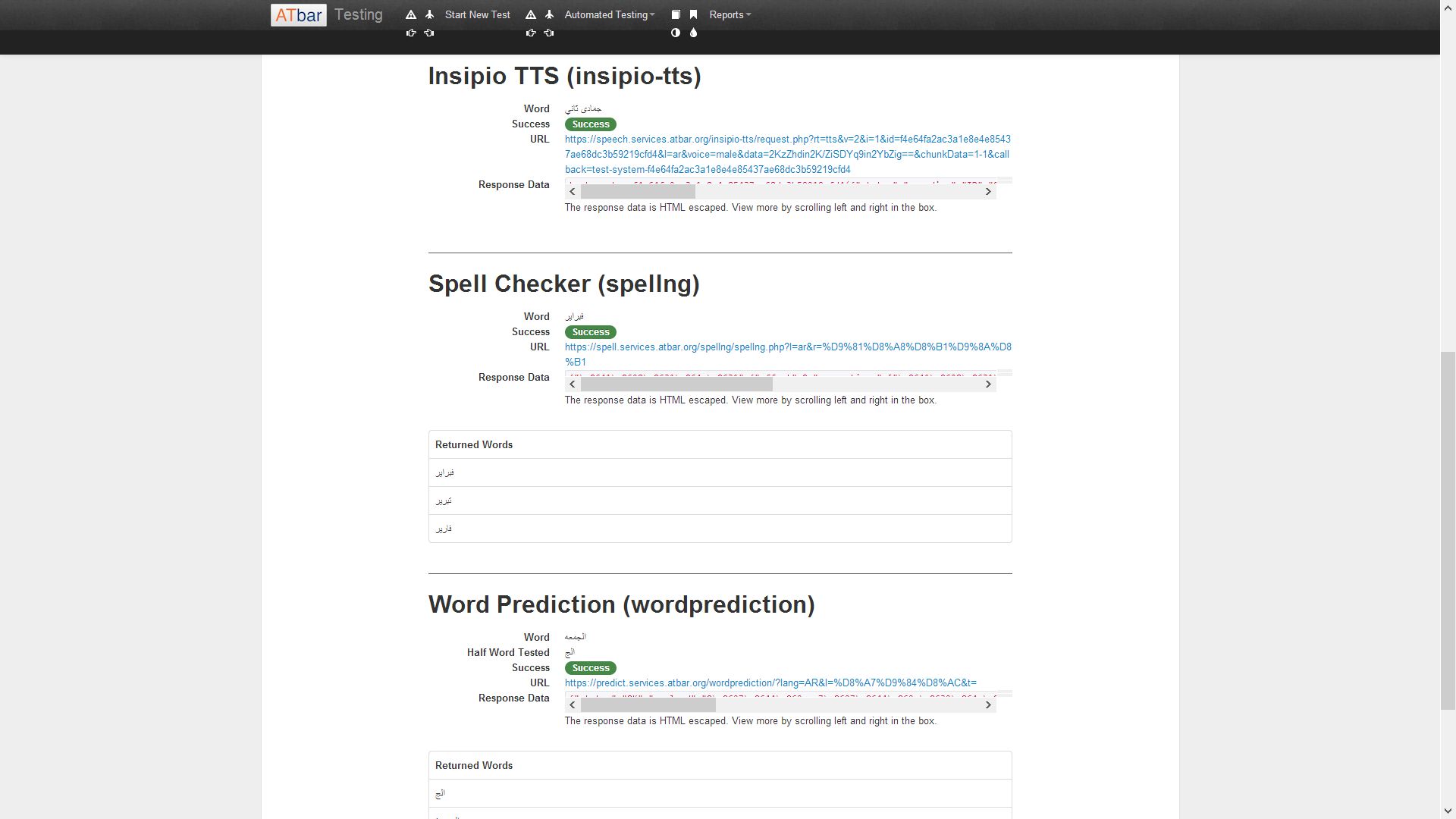
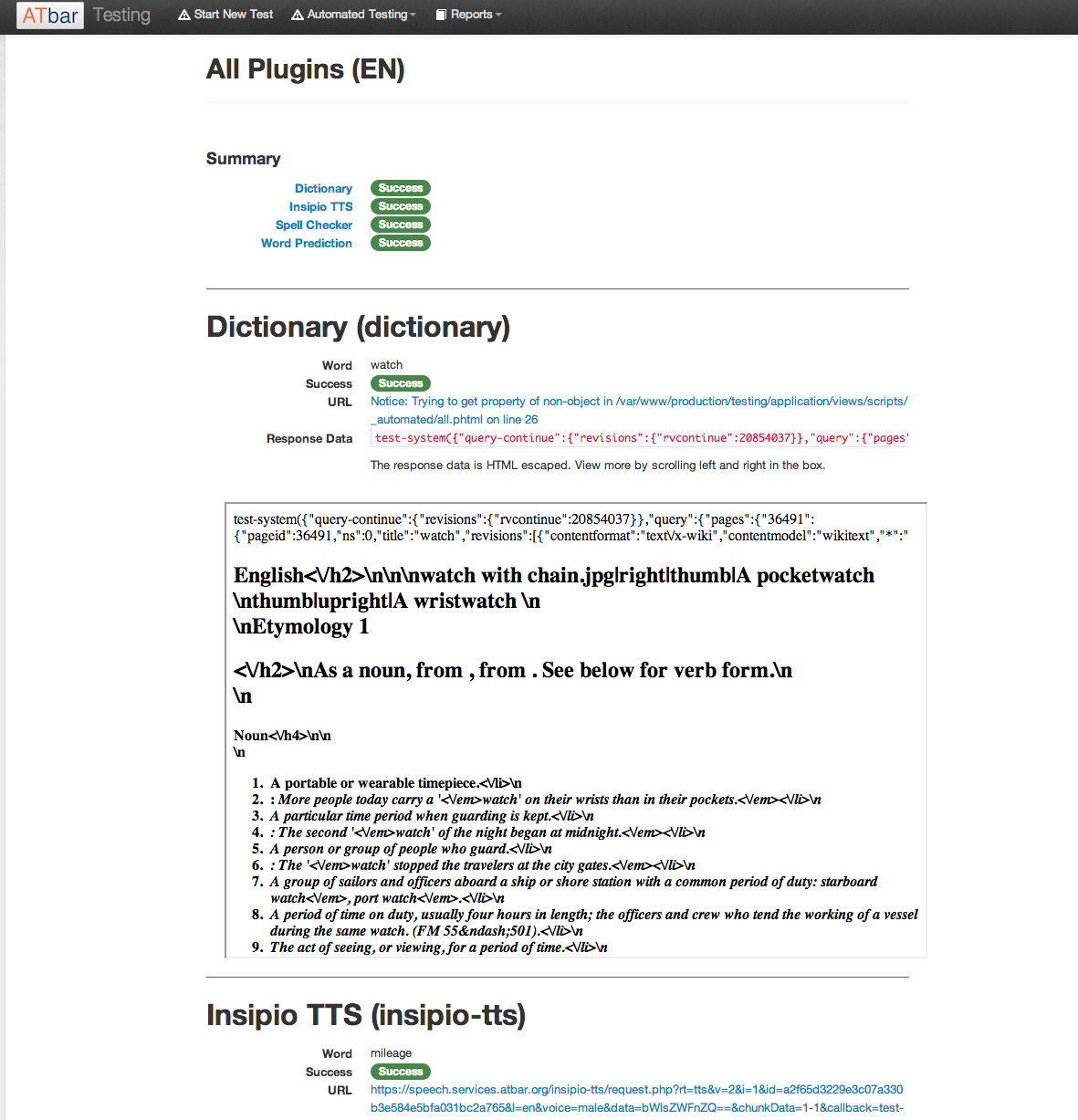
Magnus has developed a testing system that not only allows us to record manual checks but also offers the chance for automated checks to take place on certain plugins. To date these include the following plugins in both languages.
Dictionary
Spell checker
Text to Speech
Word Prediction
Manual tests are carried out on all plugins that affect the look and feel of the web page as a result of using the ATbar, these include:
Text resizing
Font changes
Readbility
Style changes
Colour overlays.
A series of well known websites in both languages are chosen for each test and the results are noted in a form with comments that is submitted to a database. The automated test results are recorded in a similar way.
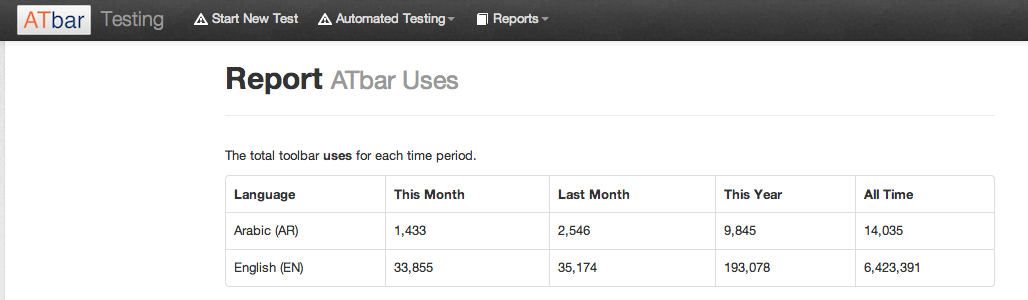
Both manual and automated results can now be seen in a report form alongside the statistics for toolbar uses. The reports are live and can be viewed at any time. The ATbar testing page with report link is available on the services page.
The report showing the toolbar uses currently has monthly, last month, this year and total uses in both languages – these appear as a table and can be printed out.
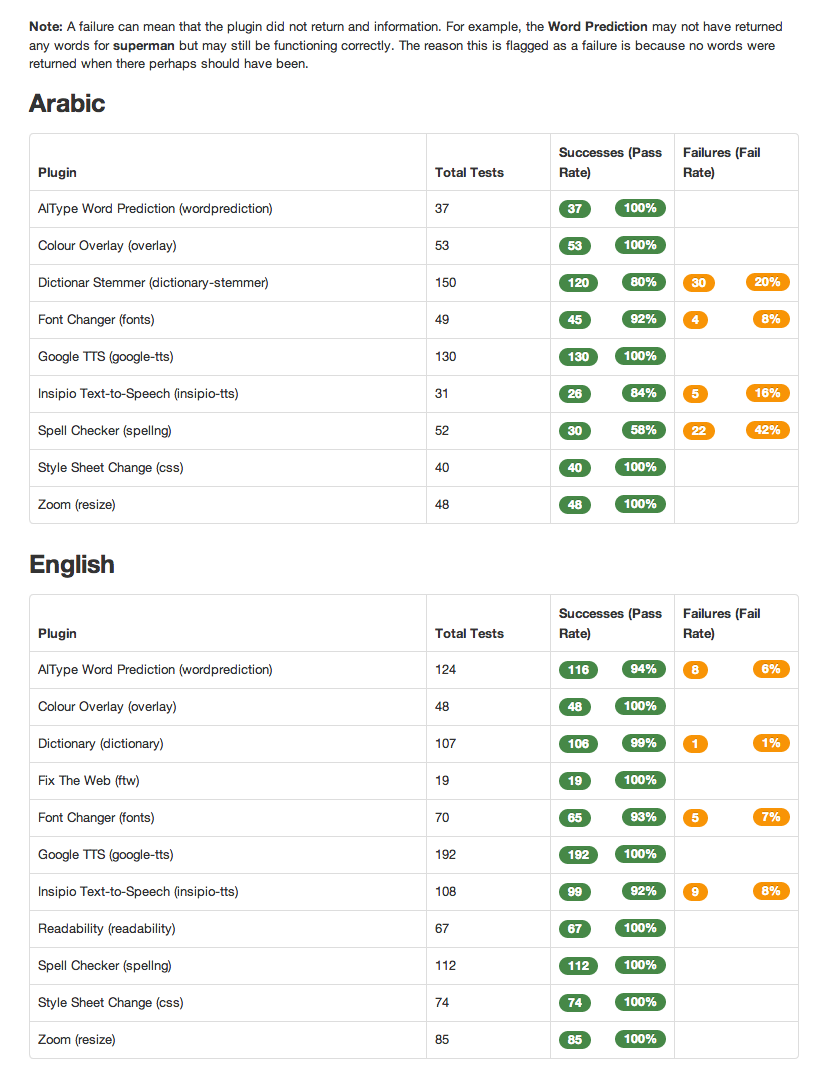
The plugin tests can be seen as a report with each plugin listed on the left of the table with total number of tests undertaken, number of successes and failures plus the percentage success and fail rate.
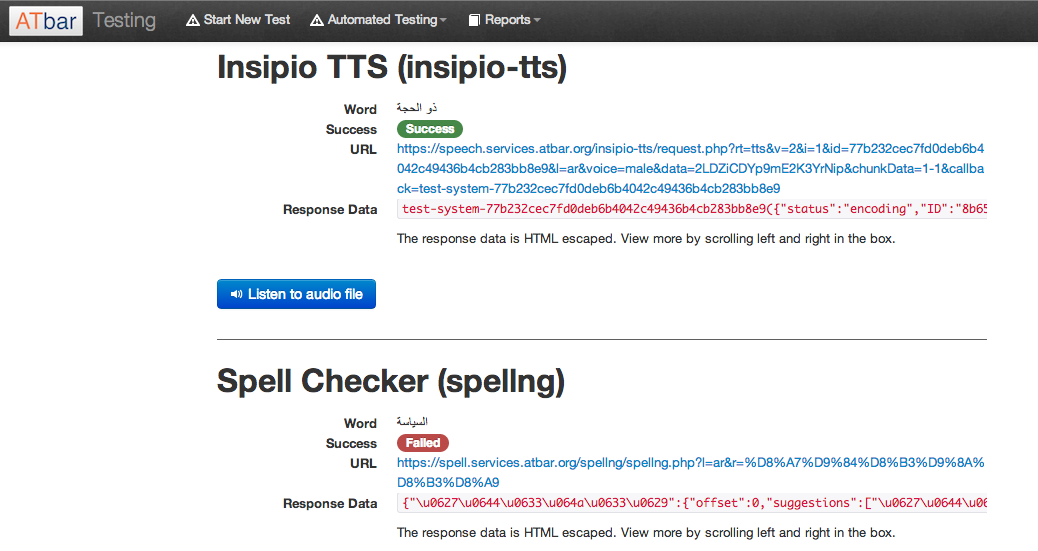
There have been some problems with returning results for the Arabic language due to retrieving UTF_8 characters from the database and encoding them to pass to the services API in order to test some plugins automatically. This is clearly a technical localisation issue and one that needs to be carefully analysed so that it can become part of the localisation framework guidance. Magnus and Russell finally solved the problem by checking the entire stack of dependencies – such as the database, web server, runtime and framework – the solution was changing the default settings in the runtime and framework to enable UTF_8 transfers. These new settings concord with those set in the database, to enable storage of text in the Arabic language. As such, we now support the Arabic language end-to-end, from database level through to the web server and browser.
One of the most vulnerable areas when testing has been the return at speed of the voices for the text to speech. This has been shortened to 2 seconds in recent months but we have noticed some lapses that may be related to the Insipio TTS servers causing intermittent availability as we have been unable to trace any other reasons at the moment. Insipio have always been incredibly helpful when issues have arisen.
Finally the testing system devised is still on trial and there is every intention to make further improvements with more automated tests that will be more accurate. This will allow us to return tests that can tell the difference between a failure and no returned data. Work is on going and it is hoped we will have the new features available soon.
We are updating ATbar all the time and working on new features such as the ability for the Text to Speech to read the Arabic dictionary if you want to highlight a definition and have it read back.
We have also found that if you maximise the Mindmeister map presented on this page by selecting the window in the map’s bottom toolbar – it opens a new window in the browser and you can launch ATbar to read the text on the mind map branches, add a tint overlay, use the dictionary etc.
The plan is to develop an automatic checking system to make sure the toolbar is always up and running as well as allowing us to keep individual statistics on each plugin so that we know they are robust over time. This will help us when we complete quarterly reports.
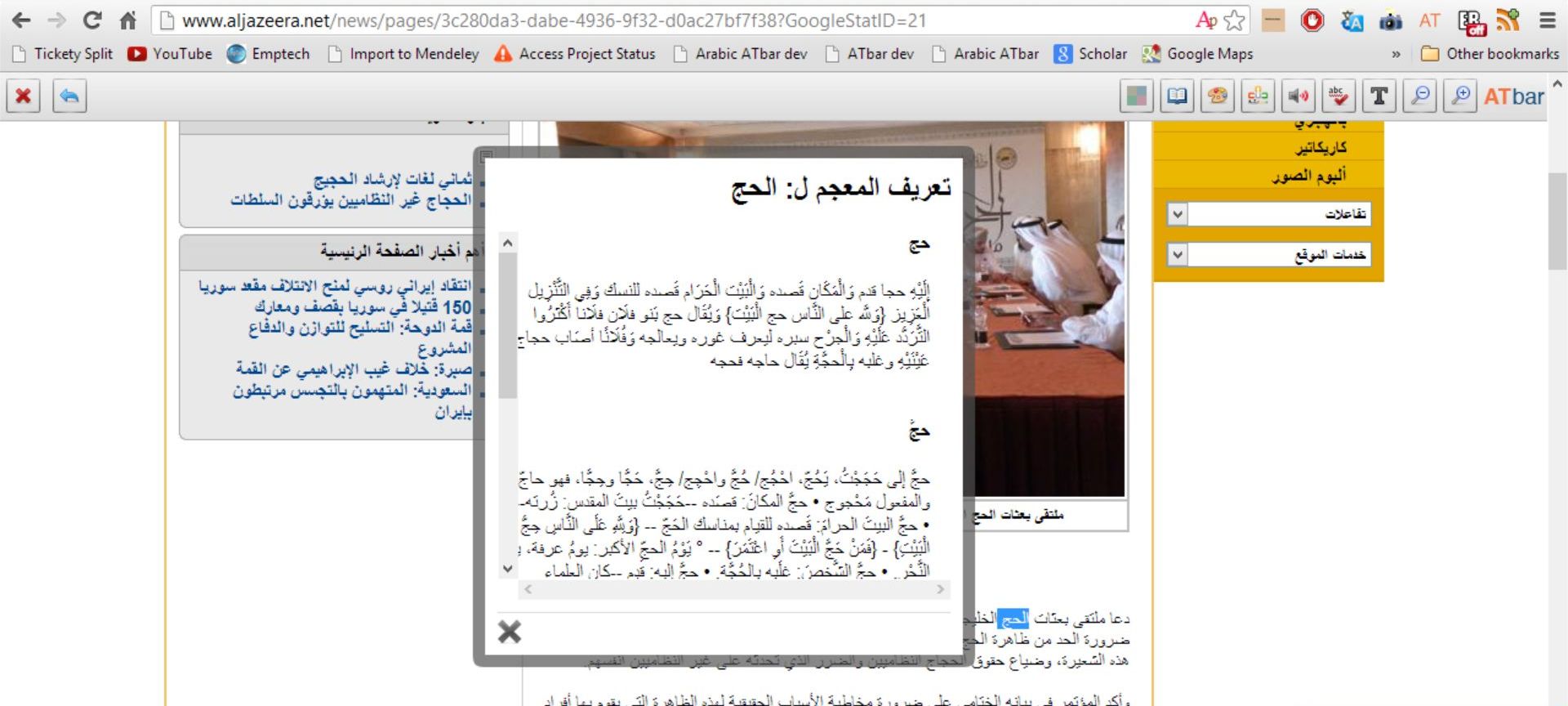
There is a consensus that Arabic dictionaries,
whether printed or electronic are not user-friendly.
Rather than being tools for learning, they are a
hindrance. Their complexity and their presentations are
not conducive to learning. Consequently, their impact
on vocabulary acquisition, even though not formally
assessed, is highly negative. (Belkhouche et al, 2011)
The authors of the paper go on to say that “the printed Arabic dictionary provides a low quality, a poor presentation, a disorganized structure, and an unscientific approach. A cursory browsing of Arabic dictionaries on the library shelves highlights these deficiencies.“
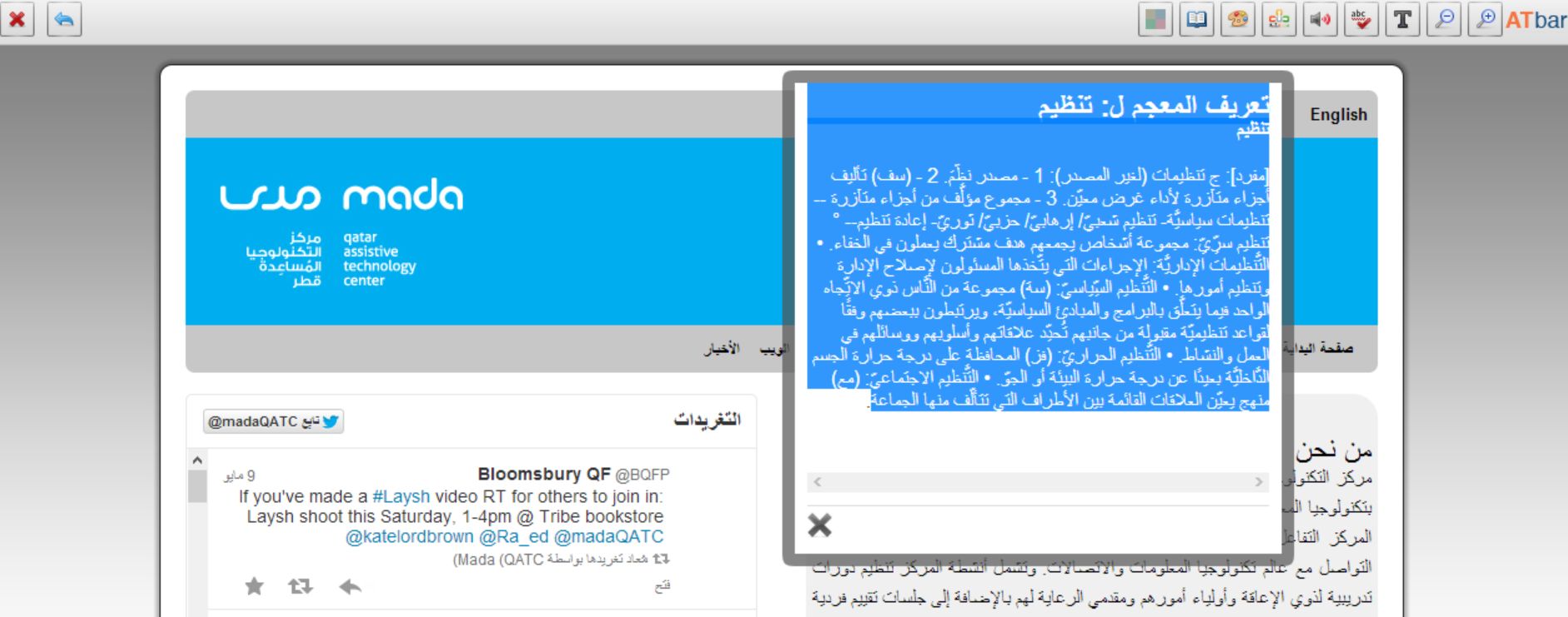
Nawar and Magnus have completed the work on a new online Arabic dictionary. This has now become part of the standard Arabic ATbar and we would be very grateful if it could be tested as much as possible.
Nawar tells me that “the dictionary database includes data from two modernized Arabic dictionaries (for word look-ups) and one traditional dictionary for root look-ups. More data can be easily added in. The dictionary plugin does not only use exact match to search for words and roots in the database, but also, it uses a light stemming algorithm to increase the reliability of the search. Prefixes and suffixes and the definite articles are removed if exact matching does not return results. The order in which these prefixes and suffixes are removed is not random but based on knowledge in the language and has been tested before for applications in information retrieval.”
The suggested hybrid retrieval approach employs various clustering and
classification methods that enhances both retrieval and presentation, and infers
further information from the results returned by a primary retrieval engine,
which, in turn, uses Latent Semantic Analysis (LSA) as a primary retrieval
method. In addition, a stemmer for Arabic words was designed and
implemented to facilitate the indexing process and to enhance the quality of
retrieval.
The dictionary database was then set up by Magnus to link with any words selected on a web page and depending on the choice of a root or the word for a definition – results are shown in what is hoped to be the most helpful way possible.
We are incredibly grateful to the work of Nawar and his brother as well as Magnus as we feel this is a first in terms of how a dictionary can be presented as an online browser plugin to support those reading Arabic texts. We are aware more dictionaries can be added and possible improvements can be made, but we need feedback as to how useful this dictionary is to users. Please leave comments!
Whilst looking at all the speech recognition apps and software available for those wishing to use Arabic speech recognition there has been some very good news and as a result I am copying the entire blog written by by Nina Curley, March 11, 2012 from Wamda
“Developers throughout the Arab World should be excited- Google’s quiet rollout of Arabic voice recognition continues to create new opportunities for localized apps.
Voice Search, an app which allows users to search by simply using their voices, launched in December but has now expanded to recognize speech in eight dialects, including, as we understand it, Jordanian, Kuwaiti, Lebanese, Qatari, Saudi, Emirati, Egyptian, and Palestinian Arabic.
“I’ve never been this excited about a product in my life,” says MENA Product Marketing Manager Najeeb Jarrar, who was on the in-house team that worked for over two years to hone the app.
Google not only tackled a different algorithmic issue, from an engineering and linguistic perspective, he notes, but also built a product that will open up new ways of searching on the web and new opportunities for developers.
Here’s how it works: when you click the search button, your mobile device records your speech as a sound wave, and transfers it to a Google server, where it is compared to billions of sound waves to determine its meaning. Your sentence is then parsed by keywords and compared to billions of keyword combinations. Google uses the best keyword combination to return the results to your phone, all in under a second, depending on your internet connection.
“It’s as accurate as if you tried voice search in English,” says Jarrar. Voice Search also works in Google Maps to return place results.
To maximize its accuracy, the team worked hard to make the app robust, testing it while having local native speakers read popular queries in a train station, in a public cafe, or near echoes, so that it could detect speech patterns despite machine or human noise.
The app, which runs on Android and a feature in the Google Search app for iPhone and Blackberry, will also continue to get more accurate as its learns. If it doesn’t understand the user fully, Voice Search will offer a list of suggestions based on the closest matches, which the user can choose from, thus helping to improve future results.
Most importantly for entrepreneurs, Voice Search in Arabic will open up to localize apps, make programs simpler to use, and increase accessibility for less tech literate populations. Because Arabic voice recognition is included in the Google Voice Search API, developers can just load the API and select the dialect of their choice.
Some of the ideas that I saw recently pitched at Startup Weekend Amman and QITCOM could certainly benefit. “Maybe we’ll start seeing games where [people] are playing simply by speaking,” offers Jarrar.
Especially where those games or apps are educational- it would be great to see this space use Arabic Voice Search to expand flexibility when it comes to including different types of learners.
Demo below [Arabic]. The Google Voice application for iPhone is available in the iTunes Store and for Android as part of Google Play.
—
Nina is the Editor-in-Chief at Wamda. You can reach her through Wamda, on Twitter @9aa, on Facebook, Google+ or at nina [AT] wamda.com.

 A group of us met up over lunch to test ATbar on a series of portable devices. This was very much a ‘beta’ testing session with critical friends. We filled in a test form and the results were analysed.
A group of us met up over lunch to test ATbar on a series of portable devices. This was very much a ‘beta’ testing session with critical friends. We filled in a test form and the results were analysed.